Migrating from Snowflake to ClickHouse
Users looking to migrate data between Snowflake and ClickHouse should use an object store, such as S3, as intermediate storage for transfer. This process relies on using the commands COPY INTO from Snowflake and INSERT INTO SELECT of ClickHouse. We outline this process below.
1. Exporting data from Snowflake
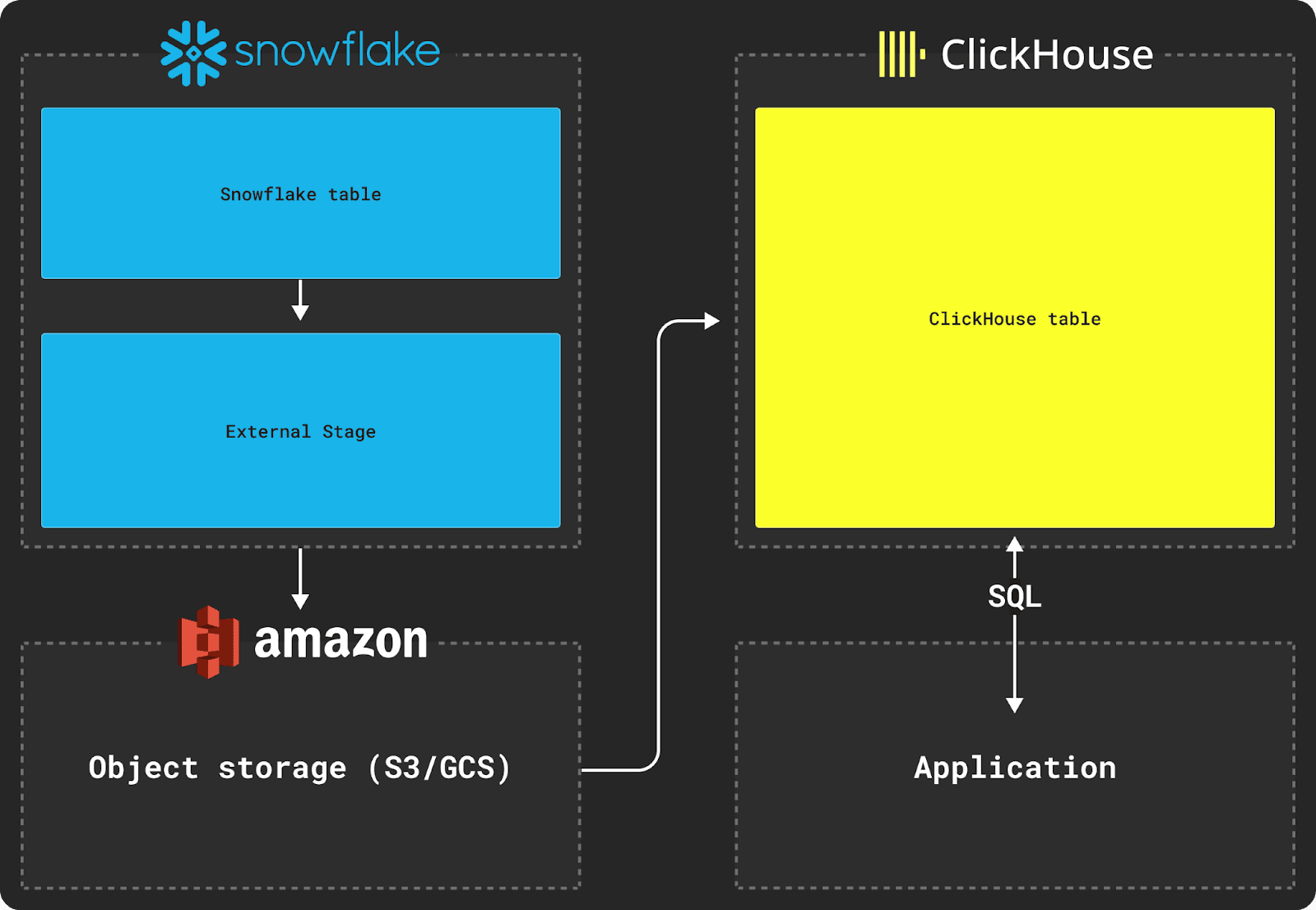
Exporting data from Snowflake requires the use of an External Stage, as shown in the diagram above.
Let's say we want to export a Snowflake table with the following schema:
CREATE TABLE MYDATASET (
timestamp TIMESTAMP,
some_text varchar,
some_file OBJECT,
complex_data VARIANT,
) DATA_RETENTION_TIME_IN_DAYS = 0;
We need to copy this data to an external stage (an S3 bucket). When copying data, we recommend Parquet as the intermittent format as it allows type information to be shared, preserves precision, compresses well, and natively supports nested structures common in analytics.
In the example below, we create a named file format in Snowflake to represent Parquet and the desired file options. This is then used when declaring an external stage (an S3 bucket) with which the COPY INTO command will be used.
CREATE FILE FORMAT my_parquet_format TYPE = parquet;
-- Create the external stage that specifies the S3 bucket to copy into
CREATE OR REPLACE STAGE external_stage
URL='s3://mybucket/mydataset'
CREDENTIALS=(AWS_KEY_ID='<key>' AWS_SECRET_KEY='<secret>')
FILE_FORMAT = my_parquet_format;
-- Apply "mydataset" prefix to all files and specify a max file size of 150mb
COPY INTO @external_stage/mydataset from mydataset max_file_size=157286400 header=true;
For a dataset around 5TB of data with a maximum file size of 150MiB, and using a 2X-LARGE warehouse located in the same AWS us-east-1 region, copying data to the S3 bucket will take around 30 mins. The header=true parameter here is required to get column names. The VARIANT and OBJECT columns in the original Snowflake table schema will also be output as JSON strings by default, forcing us to cast these when inserting them into ClickHouse.
2. Importing to ClickHouse
Once the data is staged in intermediary object storage, ClickHouse functions such as the s3 table function can be used to insert the data into a table, as shown below.
Assuming the following table target schema:
CREATE TABLE default.mydataset
(
`timestamp` DateTime64(6),
`some_text` String,
`some_file` Tuple(filename String, version String),
`complex_data` Tuple(name String, description String),
)
ENGINE = MergeTree
ORDER BY (date, timestamp)
With nested structures such as file converted to JSON strings by Snowflake, importing this data thus requires us to transform these structures to appropriate Tuples at insert time in ClickHouse, using the JSONExtract function as shown below.
INSERT INTO mydataset
SELECT
timestamp,
some_text,
JSONExtract(ifNull(FILE, '{}'), 'Tuple(filename String, version String)') AS file,
JSONExtract(ifNull(FILE, '{}'), 'Tuple(filename String, version description)') AS complex_data,
FROM s3('https://my-bucket.s3.eu-west-3.amazonaws.com/mydataset/2023/mydataset*.parquet')
SETTINGS input_format_null_as_default = 1, input_format_parquet_case_insensitive_column_matching = 1
We rely on the settings input_format_null_as_default=1 and input_format_parquet_case_insensitive_column_matching=1 here to ensure columns are inserted as default values if null, and column matching between the source data and target table is case insensitive.
To test whether your data was properly inserted, simply just run a query on your new table:
SELECT * FROM mydataset limit 10;
If using Azure or Google Cloud, similar processes can be created. Note that dedicated functions exist in ClickHouse for importing data from these object stores.